What is StepVideo T2V?
StepVideoT2V is a state-of-the-art text-to-video pre-trained model featuring 30 billion parameters, capable of generating videos up to 204 frames in length.
It uses a deep compression Variational Autoencoder (Video-VAE) designed for video generation tasks, achieving 16x16 spatial and 8x temporal compression ratios while maintaining exceptional video reconstruction quality. The model supports both English and Chinese inputs through its bilingual text encoders.
A DiT with 3D full attention is employed to denoise input noise into latent frames, and a video-based Direct Preference Optimization (Video-DPO) approach is applied to reduce artifacts and enhance the visual quality of the generated videos.
StepVideoT2V's performance is evaluated on a novel video generation benchmark, Step-Video-T2V-Eval, showcasing its superior text-to-video quality compared to other engines.
Introduction to StepVideoT2V
Step-Video-T2V is a cutting-edge model that turns text into video. It has 30 billion parameters and can create videos up to 204 frames long. The model uses a special technique called Video-VAE to compress video data, making it efficient while keeping the video quality high.
Model Summary
This model can understand prompts in both English and Chinese using two text encoders. It uses a method called DiT with 3D full attention to turn noise into video frames, using text and time as guides. To make videos look better, it uses Video-DPO to reduce any unwanted artifacts.
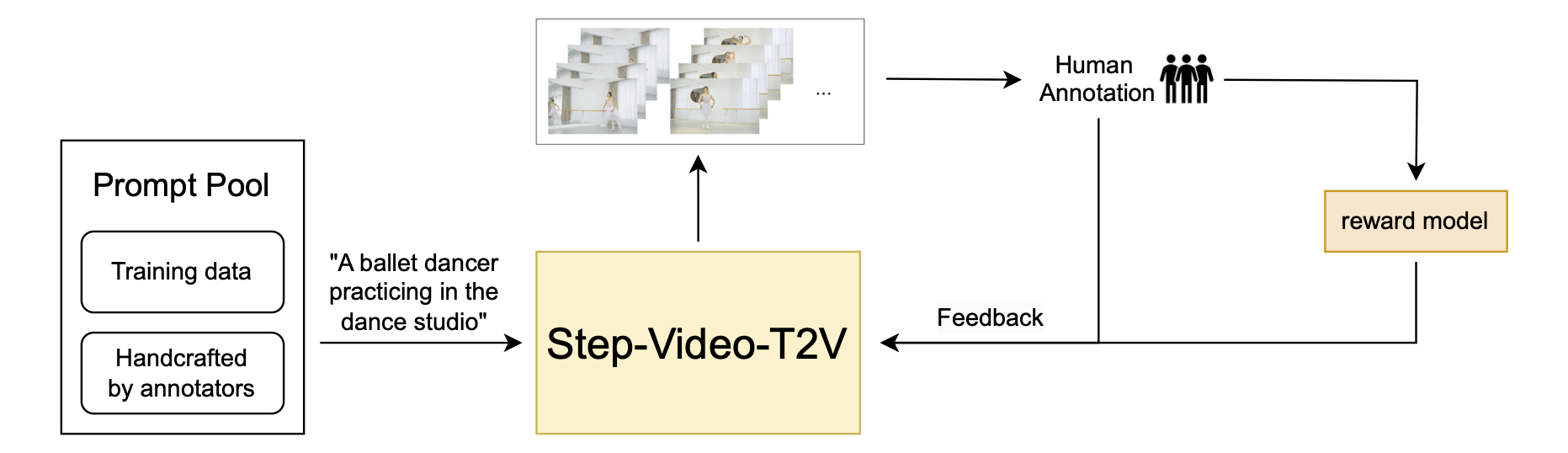
Key Components
Video-VAE: This is a tool for making videos that compresses data a lot but still keeps the video looking great.
DiT w/ 3D Full Attention: This part of the model has 48 layers and uses advanced techniques to make sure it works well and stays stable.
Video-DPO: This uses feedback from people to make the videos look even better, ensuring they meet human expectations.
Key Features of Step-Video-T2V
Video Creation
Step-Video-T2V is capable of producing videos with up to 204 frames, powered by a model containing 30 billion parameters.
Effective Data Compression
Employs Video-VAE for significant data compression, achieving 16x16 spatial and 8x temporal compression ratios while preserving video quality.
Dual-Language Text Handling
Handles user prompts in both English and Chinese using two text encoders designed for bilingual processing.
Improved Visual Output
Utilizes Video-DPO to minimize artifacts and enhance the visual quality of the videos produced.
Top-Tier Performance
Tested on the Step-Video-T2V-Eval benchmark, showcasing superior text-to-video quality compared to other systems.
Examples of StepVideo T2V in Action
1. Van Gogh in Paris
On the streets of Paris, Van Gogh is sitting outside a cafe, painting a night scene with a drawing board in his hand. The camera is shot in a medium shot, showing his focused expression and fast-moving brush. The street lights and pedestrians in the background are slightly blurred, using a shallow depth of field to highlight his image. As time passes, the sky changes from dusk to night, and the stars gradually appear. The camera slowly pulls away to see the comparison between his finished work and the real night scene.
2. Millennium Falcon Journey
In the vast universe, the Millennium Falcon in Star Wars is traveling across the stars. The camera shows the spacecraft flying among the stars in a distant view. The camera quickly follows the trajectory of the spacecraft, showing its high-speed shuttle. Entering the cockpit, the camera focuses on the facial expressions of Han Solo and Chewbacca, who are nervously operating the instruments. The lights on the dashboard flicker, and the background starry sky quickly passes by outside the porthole.
3. Astronauts on the Moon
The astronauts run on the lunar surface, and the low-angle shot shows the vast background of the moon. The movements are smooth and light.
4. Dachshund's Joyful Dive
A cinematic, high-action tracking shot follows an incredibly cute dachshund wearing swimming goggles as it leaps into a crystal-clear pool. The camera plunges underwater with the dog, capturing the joyful moment of submersion and the ensuing flurry of paddling with adorable little paws. Sunlight filters through the water, illuminating the dachshund's sleek, wet fur and highlighting the determined expression on its face. The shot is filled with the vibrant blues and greens of the pool water, creating a dynamic and visually stunning sequence that captures the pure joy and energy of the swimming dachshund.
Open-Source Model and Licensing
StepVideo has made the Step-Video-T2V model available under the MIT license. This means:
- The model can be used for commercial purposes
- Users can modify and distribute the model
- The model weights are available, allowing for fine-tuning on specific domains
This open-source initiative enables developers to explore and enhance the model's capabilities.
Pros and Cons
Pros
- AI Video model
- High video quality
- Efficient compression ratios
- Bilingual text support
- Reduces video artifacts
Cons
- High GPU memory requirement
- Complex setup process
How to use Step-Video-T2V using Github?
Step 1: Install Required Software
Make sure you have Python >= 3.10, PyTorch >= 2.3-cu121, and the CUDA Toolkit installed. Anaconda is recommended for setting up the environment.
Step 2: Get the Code
Use the command below to download the Step-Video-T2V repository from GitHub:
git clone https://github.com/StepVideo-ai/Step-Video-T2V.gitMove into the project directory:
cd Step-Video-T2VStep 3: Configure Environment
Set up and activate a conda environment:
conda create -n stepvideo python=3.10
conda activate stepvideoInstall the required packages:
pip install -e .
pip install flash-attn --no-build-isolation ## flash-attn is optionalStep 4: Obtain the Model
Acquire the Step-Video-T2V model from Huggingface or Modelscope to use in video creation.
Step 5: Deploy with Multiple GPUs
StepVideo AI uses a separation method for the text encoder, VAE decoding, and DiT to make the most of GPU resources. A dedicated GPU is required to manage the API services for the text encoder's embeddings and VAE decoding.
python api/call_remote_server.py --model_dir where_you_download_dir &This command will provide the URL for both the caption API and the VAE API. Use the given URL in the next command.
Step 6: Perform Inference
Run the inference script with the necessary parameters to create videos from text inputs.
Step 7: Fine-Tune Settings
Modify inference settings like infer_steps, cfg_scale, and time_shift to achieve the best video quality.
Creating Videos with StepVideo AI
Step 1: Access the Platform
Head over to the StepVideo AI video creation site by navigating to yuewen.cn/videos.
Step 2: Input Your Text
On the platform, find the text input area. Type in the text you want to convert into a video.
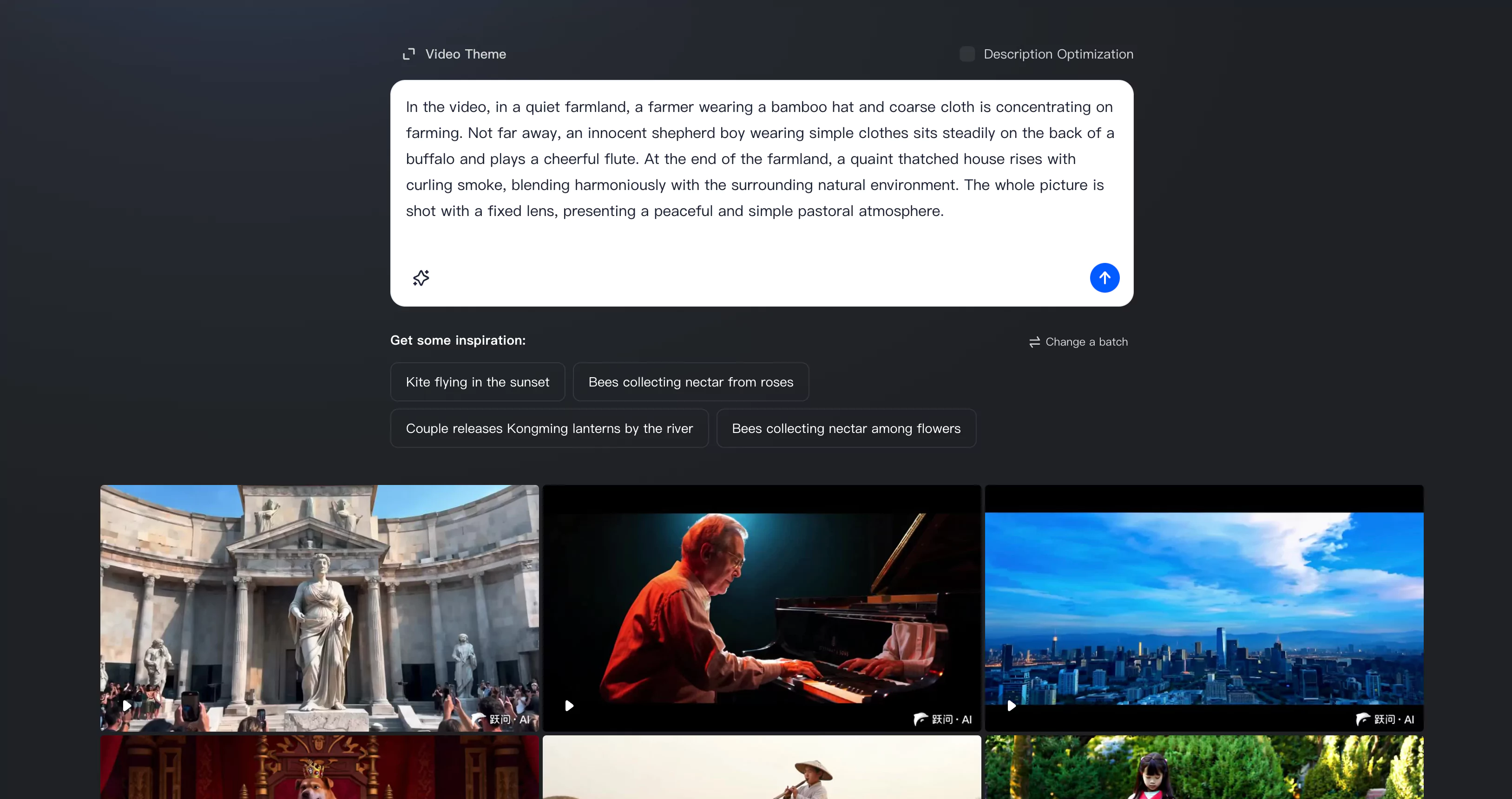
Step 3: Initiate Video Creation
After entering your text, press the "Generate" button to start the video creation. The system will analyze your input and produce a video accordingly.
Step 4: Account Access (if required)
You might be asked to log in or create an account to use the video generation features. Follow the instructions on the screen to complete this process.